
MongoDB Atlas With Terraform - Cluster and Backup Policies
Published in MongoDB Developer Center, 2024
In this tutorial, I will show you how to create a MongoDB cluster in Atlas using Terraform. We saw in a previous article how to create an API key to start using Terraform and create our first project module. Now, we will go ahead and create our first cluster. If you don’t have an API key and a project, I recommend you look at the previous article.
This article is for anyone who intends to use or already uses infrastructure as code (IaC) on the MongoDB Atlas platform or wants to learn more about it.
Everything we do here is contained in the provider/resource documentation: mongodbatlas_advanced_cluster
Note: We will not use a backend file. However, for productive implementations, it is extremely important and safer to store the state file in a remote location such as an S3, GCS, Azurerm, etc…
Creating a cluster
At this point, we will create our first replica set cluster using Terraform in MongoDB Atlas. As discussed in the previous article, Terraform is a powerful infrastructure-as-code tool that allows you to manage and provision IT resources in an efficient and predictable way. By using it in conjunction with MongoDB Atlas, you can automate the creation and management of database resources in the cloud, ensuring a consistent and reliable infrastructure.
Before we begin, make sure that all the prerequisites mentioned in the previous article are properly configured: Install Terraform, create an API key in MongoDB Atlas, and set up a project in Atlas. These steps are essential to ensure the success of creating your replica set cluster.
Terraform provider configuration for MongoDB Atlas
The first step is to configure the Terraform provider for MongoDB Atlas. This will allow Terraform to communicate with the MongoDB Atlas API and manage resources within your account. Add the following block of code to your provider.tf file:
provider "mongodbatlas" {}
In the previous article, we configured the Terraform provider by directly entering our public and private keys. Now, in order to adopt more professional practices, we have chosen to use environment variables for authentication. The MongoDB Atlas provider, like many others, supports several authentication methodologies. The safest and most recommended option is to use environment variables. This implies only defining the provider in our Terraform code and exporting the relevant environment variables where Terraform will be executed, whether in the terminal, as a secret in Kubernetes, or a secret in GitHub Actions, among other possible contexts. There are other forms of authentication, such as using MongoDB CLI, AWS Secrets Manager, directly through variables in Terraform, or even specifying the keys in the code. However, to ensure security and avoid exposing our keys in accessible locations, we opt for the safer approaches mentioned.
Creating the Terraform version file
Inside the versions.tf file, you will start by specifying the version of Terraform that your project requires. This is important to ensure that all users and CI/CD environments use the same version of Terraform, avoiding possible incompatibilities or execution errors. In addition to defining the Terraform version, it is equally important to specify the versions of the providers used in your project. This ensures that resources are managed consistently. For example, to set the MongoDB Atlas provider version, you would add a required_providers block inside the Terraform block, as shown below:
terraform {
required_version = ">= 0.12"
required_providers {
mongodbatlas = {
source = "mongodb/mongodbatlas"
version = "1.14.0"
}
}
}
Defining the cluster resource
After configuring the version file and establishing the Terraform and provider versions, the next step is to define the cluster resource in MongoDB Atlas. This is done by creating a .tf file, for example main.tf, where you will specify the properties of the desired cluster. As we are going to make a module that will be reusable, we will use variables and default values so that other calls can create clusters with different architectures or sizes, without having to write a new module.
I will look at some attributes and parameters to make this clear.
# ------------------------------------------------------------------------------
# MONGODB CLUSTER
# ------------------------------------------------------------------------------
resource "mongodbatlas_advanced_cluster" "default" {
project_id = data.mongodbatlas_project.default.id
name = var.name
cluster_type = var.cluster_type
backup_enabled = var.backup_enabled
pit_enabled = var.pit_enabled
mongo_db_major_version = var.mongo_db_major_version
disk_size_gb = var.disk_size_gb
In this first block, we are specifying the name of our cluster through the name parameter, its type (which can be a REPLICASET, SHARDED, or GEOSHARDED), and if we have backup and point in time activated, in addition to the database version and the amount of storage for the cluster.
advanced_configuration {
fail_index_key_too_long = var.fail_index_key_too_long
javascript_enabled = var.javascript_enabled
minimum_enabled_tls_protocol = var.minimum_enabled_tls_protocol
no_table_scan = var.no_table_scan
oplog_size_mb = var.oplog_size_mb
default_read_concern = var.default_read_concern
default_write_concern = var.default_write_concern
oplog_min_retention_hours = var.oplog_min_retention_hours
transaction_lifetime_limit_seconds = var.transaction_lifetime_limit_seconds
sample_size_bi_connector = var.sample_size_bi_connector
sample_refresh_interval_bi_connector = var.sample_refresh_interval_bi_connector
}
Here, we are specifying some advanced settings. Many of these values will not be specified in the .tfvars as they have default values in the variables.tf file. Parameters include the type of read/write concern, oplog size in MB, TLS protocol, whether JavaScript will be enabled in MongoDB, and transaction lifetime limit in seconds. no_table_scan is for when the cluster disables the execution of any query that requires a collection scan to return results, when true. There are more parameters that you can look at in the documentation, if you have questions.
replication_specs {
num_shards = var.cluster_type == "REPLICASET" ? null : var.num_shards
dynamic "region_configs" {
for_each = var.region_configs
content {
provider_name = region_configs.value.provider_name
priority = region_configs.value.priority
region_name = region_configs.value.region_name
electable_specs {
instance_size = region_configs.value.electable_specs.instance_size
node_count = region_configs.value.electable_specs.node_count
disk_iops = region_configs.value.electable_specs.instance_size == "M10" || region_configs.value.electable_specs.instance_size == "M20" ? null : region_configs.value.electable_specs.disk_iops
ebs_volume_type = region_configs.value.electable_specs.ebs_volume_type
}
auto_scaling {
disk_gb_enabled = region_configs.value.auto_scaling.disk_gb_enabled
compute_enabled = region_configs.value.auto_scaling.compute_enabled
compute_scale_down_enabled = region_configs.value.auto_scaling.compute_scale_down_enabled
compute_min_instance_size = region_configs.value.auto_scaling.compute_min_instance_size
compute_max_instance_size = region_configs.value.auto_scaling.compute_max_instance_size
}
analytics_specs {
instance_size = try(region_configs.value.analytics_specs.instance_size, "M10")
node_count = try(region_configs.value.analytics_specs.node_count, 0)
disk_iops = try(region_configs.value.analytics_specs.disk_iops, null)
ebs_volume_type = try(region_configs.value.analytics_specs.ebs_volume_type, "STANDARD")
}
analytics_auto_scaling {
disk_gb_enabled = try(region_configs.value.analytics_auto_scaling.disk_gb_enabled, null)
compute_enabled = try(region_configs.value.analytics_auto_scaling.compute_enabled, null)
compute_scale_down_enabled = try(region_configs.value.analytics_auto_scaling.compute_scale_down_enabled, null)
compute_min_instance_size = try(region_configs.value.analytics_auto_scaling.compute_min_instance_size, null)
compute_max_instance_size = try(region_configs.value.analytics_auto_scaling.compute_max_instance_size, null)
}
read_only_specs {
instance_size = try(region_configs.value.read_only_specs.instance_size, "M10")
node_count = try(region_configs.value.read_only_specs.node_count, 0)
disk_iops = try(region_configs.value.read_only_specs.disk_iops, null)
ebs_volume_type = try(region_configs.value.read_only_specs.ebs_volume_type, "STANDARD")
}
}
}
}
At this moment, we are placing the number of shards we want, in case our cluster is not a REPLICASET. In addition, we specify the configuration of the cluster, region, cloud, priority for failover, autoscaling, electable, analytics, and read-only node configurations, in addition to its autoscaling configurations.
dynamic "tags" {
for_each = local.tags
content {
key = tags.key
value = tags.value
}
}
bi_connector_config {
enabled = var.bi_connector_enabled
read_preference = var.bi_connector_read_preference
}
lifecycle {
ignore_changes = [
disk_size_gb,
]
}
}
Next, we create a dynamic block to loop for each tag variable we include. In addition, we specify the BI connector, if desired, and the lifecycle block. Here, we are only specifying disk_size_gb for an example, but it is recommended to read the documentation that has important warnings about this block, such as including instance_size, as autoscaling can change and you don’t want to accidentally retire an instance during peak times.
# ------------------------------------------------------------------------------
# MONGODB BACKUP SCHEDULE
# ------------------------------------------------------------------------------
resource "mongodbatlas_cloud_backup_schedule" "default" {
project_id = data.mongodbatlas_project.default.id
cluster_name = mongodbatlas_advanced_cluster.default.name
update_snapshots = var.update_snapshots
reference_hour_of_day = var.reference_hour_of_day
reference_minute_of_hour = var.reference_minute_of_hour
restore_window_days = var.restore_window_days
policy_item_hourly {
frequency_interval = var.policy_item_hourly_frequency_interval
retention_unit = var.policy_item_hourly_retention_unit
retention_value = var.policy_item_hourly_retention_value
}
policy_item_daily {
frequency_interval = var.policy_item_daily_frequency_interval
retention_unit = var.policy_item_daily_retention_unit
retention_value = var.policy_item_daily_retention_value
}
policy_item_weekly {
frequency_interval = var.policy_item_weekly_frequency_interval
retention_unit = var.policy_item_weekly_retention_unit
retention_value = var.policy_item_weekly_retention_value
}
policy_item_monthly {
frequency_interval = var.policy_item_monthly_frequency_interval
retention_unit = var.policy_item_monthly_retention_unit
retention_value = var.policy_item_monthly_retention_value
}
}
Finally, we create the backup block, which contains the policies and settings regarding the backup of our cluster.
This module, while detailed, encapsulates the full functionality offered by the mongodbatlas_advanced_cluster and mongodbatlas_cloud_backup_schedule resources, providing a comprehensive approach to creating and managing clusters in MongoDB Atlas. It supports the configuration of replica set, sharded, and geosharded clusters, meeting a variety of scalability and geographic distribution needs.
One of the strengths of this module is its flexibility in configuring backup policies, allowing fine adjustments that precisely align with the requirements of each database. This is essential to ensure resilience and effective data recovery in any scenario. Additionally, the module comes with vertical scaling enabled by default, in addition to offering advanced storage auto-scaling capabilities, ensuring that the cluster dynamically adjusts to the data volume and workload.
To complement the robustness of the configuration, the module allows the inclusion of analytical nodes and read-only nodes, expanding the possibilities of using the cluster for scenarios that require in-depth analysis or intensive read operations without impacting overall performance.
The default configuration includes smart preset values, such as the MongoDB version, which is set to “7.0” to take advantage of the latest features while maintaining the option to adjust to specific versions as needed. This “best practices” approach ensures a solid starting point for most projects, reducing the need for manual adjustments and simplifying the deployment process.
Additionally, the ability to deploy clusters in any region and cloud provider — such as AWS, Azure, or GCP — offers unmatched flexibility, allowing teams to choose the best solution based on their cost, performance, and compliance preferences. In summary, this module not only facilitates the configuration and management of MongoDB Atlas clusters with an extensive range of options and adjustments but also promotes secure and efficient configuration practices, making it a valuable tool for developers and database administrators in implementing scalable and reliable data solutions in the cloud.
The use of the lifecycle directive with the ignore_changes option in the Terraform code was specifically implemented to accommodate manual upscale situations of the MongoDB Atlas cluster, which should not be automatically reversed by Terraform in subsequent executions. This approach ensures that, after a manual increase in storage capacity (disk_size_gb) or other specific replication configurations (replication_specs), Terraform does not attempt to undo these changes to align the resource state with the original definition in the code. Essentially, it allows configuration adjustments made outside of Terraform, such as an upscale to optimize performance or meet growing demands, to remain intact without being overwritten by future Terraform executions, ensuring operational flexibility while maintaining infrastructure management as code.
In the variable.tf file, we create variables with default values:
variable "name" {
description = "The name of the cluster."
type = string
}
variable "cluster_type" {
description = <<HEREDOC
Optional - Specifies the type of the cluster that you want to modify. You cannot convert
a sharded cluster deployment to a replica set deployment. Accepted values include:
REPLICASET for Replica set, SHARDED for Sharded cluster, and GEOSHARDED for Global Cluster
HEREDOC
default = "REPLICASET"
}
variable "mongo_db_major_version" {
description = <<HEREDOC
Optional - Version of the cluster to deploy. Atlas supports the following MongoDB versions
for M10+ clusters: 5.0, 6.0 or 7.0.
HEREDOC
default = "7.0"
}
variable "version_release_system" {
description = <<HEREDOC
Optional - Release cadence that Atlas uses for this cluster. This parameter defaults to LTS.
If you set this field to CONTINUOUS, you must omit the mongo_db_major_version field. Atlas accepts:
CONTINUOUS - Atlas deploys the latest version of MongoDB available for the cluster tier.
LTS - Atlas deploys the latest Long Term Support (LTS) version of MongoDB available for the cluster tier.
HEREDOC
default = "LTS"
}
variable "disk_size_gb" {
description = <<HEREDOC
Optional - Capacity, in gigabytes, of the host’s root volume. Increase this
number to add capacity, up to a maximum possible value of 4096 (i.e., 4 TB). This value must
be a positive integer. If you specify diskSizeGB with a lower disk size, Atlas defaults to
the minimum disk size value. Note: The maximum value for disk storage cannot exceed 50 times
the maximum RAM for the selected cluster. If you require additional storage space beyond this
limitation, consider upgrading your cluster to a higher tier.
HEREDOC
type = number
default = 10
}
variable "backup_enabled" {
description = <<HEREDOC
Optional - Flag indicating if the cluster uses Cloud Backup for backups. If true, the cluster
uses Cloud Backup for backups. The default is true.
HEREDOC
type = bool
default = true
}
variable "pit_enabled" {
description = <<HEREDOC
Optional - Flag that indicates if the cluster uses Continuous Cloud Backup. If set to true,
backup_enabled must also be set to true. The default is true.
HEREDOC
type = bool
default = true
}
variable "disk_gb_enabled" {
description = <<HEREDOC
Optional - Specifies whether disk auto-scaling is enabled. The default is true.
HEREDOC
type = bool
default = true
}
variable "region_configs" {
description = <<HEREDOC
Required - Physical location of the region. Each regionsConfig document describes
the region’s priority in elections and the number and type of MongoDB nodes Atlas
deploys to the region. You can be set that parameters:
- region_name - Optional - Physical location of your MongoDB cluster. The region you choose can affect network latency for clients accessing your databases.
- electable_nodes - Optional - Number of electable nodes for Atlas to deploy to the region. Electable nodes can become the primary and can facilitate local reads. The total number of electableNodes across all replication spec regions must total 3, 5, or 7. Specify 0 if you do not want any electable nodes in the region. You cannot create electable nodes in a region if priority is 0.
- priority - Optional - Election priority of the region. For regions with only read-only nodes, set this value to 0. For regions where electable_nodes is at least 1, each region must have a priority of exactly one (1) less than the previous region. The first region
must have a priority of 7. The lowest possible priority is 1. The priority 7 region identifies the Preferred Region of the cluster. Atlas places the primary node in the Preferred Region. Priorities 1 through 7 are exclusive - no more than one region per cluster can be assigned a given priority. Example: If you have three regions, their priorities would be 7, 6, and 5 respectively. If you added two more regions for supporting electable nodes, the priorities of those regions would be 4 and 3 respectively.
- read_only_nodes - Optional - Number of read-only nodes for Atlas to deploy to the region.
Read-only nodes can never become the primary, but can facilitate local-reads. Specify 0 if you do not want any read-only nodes in the region.
- analytics_nodes - Optional - The number of analytics nodes for Atlas to deploy to the region.
Analytics nodes are useful for handling analytic data such as reporting queries from BI Connector for Atlas. Analytics nodes are read-only, and can never become the primary. If you do not specify this option, no analytics nodes are deployed to the region.
HEREDOC
type = any
}
# ------------------------------------------------------------------------------
# MONGODB BI CONNECTOR
# ------------------------------------------------------------------------------
variable "bi_connector_enabled" {
description = <<HEREDOC
Optional - Specifies whether or not BI Connector for Atlas is enabled on the cluster.
Set to true to enable BI Connector for Atlas. Set to false to disable BI Connector for Atlas.
HEREDOC
type = bool
default = false
}
variable "bi_connector_read_preference" {
description = <<HEREDOC
Optional - Specifies the read preference to be used by BI Connector for Atlas on the cluster.
Each BI Connector for Atlas read preference contains a distinct combination of readPreference and readPreferenceTags options. For details on BI Connector for Atlas read preferences, refer to the BI Connector Read Preferences Table.
Set to "primary" to have BI Connector for Atlas read from the primary. Set to "secondary" to have BI Connector for Atlas read from a secondary member. Default if there are no analytics nodes in the cluster. Set to "analytics" to have BI Connector for Atlas read from an analytics node. Default if the cluster contains analytics nodes.
HEREDOC
type = string
default = "secondary"
}
# ------------------------------------------------------------------------------
# MONGODB ADVANCED CONFIGURATION
# ------------------------------------------------------------------------------
variable "fail_index_key_too_long" {
description = <<HEREDOC
Optional - When true, documents can only be updated or inserted if, for all indexed fields on the target collection, the corresponding index entries do not exceed 1024 bytes. When false, mongod writes documents that exceed the limit but does not index them.
HEREDOC
type = bool
default = false
}
variable "javascript_enabled" {
description = <<HEREDOC
Optional - When true, the cluster allows execution of operations that perform server-side executions of JavaScript. When false, the cluster disables execution of those operations.
HEREDOC
type = bool
default = true
}
variable "minimum_enabled_tls_protocol" {
description = <<HEREDOC
Optional - Sets the minimum Transport Layer Security (TLS) version the cluster accepts for incoming connections. Valid values are: TLS1_0, TLS1_1, TLS1_2. The default is "TLS1_2".
HEREDOC
default = "TLS1_2"
}
variable "no_table_scan" {
description = <<HEREDOC
Optional - When true, the cluster disables the execution of any query that requires a collection scan to return results. When false, the cluster allows the execution of those operations.
HEREDOC
type = bool
default = false
}
variable "oplog_size_mb" {
description = <<HEREDOC
Optional - The custom oplog size of the cluster.
Without a value that indicates that the cluster uses the default oplog size calculated by Atlas.
HEREDOC
type = number
default = null
}
variable "default_read_concern" {
description = <<HEREDOC
Optional - The default read concern for the cluster. The default is "local".
HEREDOC
default = "local"
}
variable "default_write_concern" {
description = <<HEREDOC
Optional - The default write concern for the cluster. The default is "majority".
HEREDOC
default = "majority"
}
variable "oplog_min_retention_hours" {
description = <<HEREDOC
Minimum retention window for cluster's oplog expressed in hours.
A value of null indicates that the cluster uses the default minimum oplog window that MongoDB Cloud calculates.
HEREDOC
type = number
default = null
}
variable "transaction_lifetime_limit_seconds" {
description = <<HEREDOC
Optional - Lifetime, in seconds, of multi-document transactions. Defaults to 60 seconds.
HEREDOC
type = number
default = 60
}
variable "sample_size_bi_connector" {
description = <<HEREDOC
Optional - Number of documents per database to sample when gathering schema information. Defaults to 100.
Available only for Atlas deployments in which BI Connector for Atlas is enabled.
HEREDOC
type = number
default = 100
}
variable "sample_refresh_interval_bi_connector" {
description = <<HEREDOC
Optional - Interval in seconds at which the mongosqld process re-samples data to create its relational schema. The default value is 300.
The specified value must be a positive integer.
Available only for Atlas deployments in which BI Connector for Atlas is enabled.
HEREDOC
type = number
default = 300
}
# ------------------------------------------------------------------------------
# MONGODB REPLICATION SPECS
# ------------------------------------------------------------------------------
variable "num_shards" {
description = <<HEREDOC
Optional - Number of shards, minimum 1.
The default is null if type is REPLICASET.
HEREDOC
type = number
default = null
}
# ------------------------------------------------------------------------------
# MONGODB BACKUP POLICY
# ------------------------------------------------------------------------------
variable "update_snapshots" {
description = <<HEREDOC
Optional - Specify true to apply the retention changes in the updated backup policy to snapshots that Atlas took previously.
HEREDOC
type = bool
default = false
}
variable "reference_hour_of_day" {
description = <<HEREDOC
Optional - Hour of the day in UTC at which Atlas takes the daily snapshots of the cluster.
HEREDOC
type = number
default = 3
}
variable "reference_minute_of_hour" {
description = <<HEREDOC
Optional - Minute of the hour in UTC at which Atlas takes the daily snapshots of the cluster.
HEREDOC
type = number
default = 30
}
variable "restore_window_days" {
description = <<HEREDOC
Optional - Number of days Atlas retains the backup snapshots in the snapshot schedule.
HEREDOC
type = number
default = 3
}
variable "policy_item_hourly_frequency_interval" {
description = <<HEREDOC
Optional - Interval, in hours, between snapshots that Atlas takes of the cluster.
HEREDOC
type = number
default = 12
}
variable "policy_item_hourly_retention_unit" {
description = <<HEREDOC
Optional - Unit of time that Atlas retains each snapshot in the hourly snapshot schedule.
HEREDOC
type = string
default = "days"
}
variable "policy_item_hourly_retention_value" {
description = <<HEREDOC
Optional - Number of units of time that Atlas retains each snapshot in the hourly snapshot schedule.
HEREDOC
type = number
default = 3
}
variable "policy_item_daily_frequency_interval" {
description = <<HEREDOC
Optional - Interval, in days, between snapshots that Atlas takes of the cluster.
HEREDOC
type = number
default = 1
}
variable "policy_item_daily_retention_unit" {
description = <<HEREDOC
Optional - Unit of time that Atlas retains each snapshot in the daily snapshot schedule.
HEREDOC
type = string
default = "days"
}
variable "policy_item_daily_retention_value" {
description = <<HEREDOC
Optional - Number of units of time that Atlas retains each snapshot in the daily snapshot schedule.
HEREDOC
type = number
default = 7
}
variable "policy_item_weekly_frequency_interval" {
description = <<HEREDOC
Optional - Interval, in weeks, between snapshots that Atlas takes of the cluster.
HEREDOC
type = number
default = 1
}
variable "policy_item_weekly_retention_unit" {
description = <<HEREDOC
Optional - Unit of time that Atlas retains each snapshot in the weekly snapshot schedule.
HEREDOC
type = string
default = "weeks"
}
variable "policy_item_weekly_retention_value" {
description = <<HEREDOC
Optional - Number of units of time that Atlas retains each snapshot in the weekly snapshot schedule.
HEREDOC
type = number
default = 4
}
variable "policy_item_monthly_frequency_interval" {
description = <<HEREDOC
Optional - Interval, in months, between snapshots that Atlas takes of the cluster.
HEREDOC
type = number
default = 1
}
variable "policy_item_monthly_retention_unit" {
description = <<HEREDOC
Optional - Unit of time that Atlas retains each snapshot in the monthly snapshot schedule.
HEREDOC
type = string
default = "months"
}
variable "policy_item_monthly_retention_value" {
description = <<HEREDOC
Optional - Number of units of time that Atlas retains each snapshot in the monthly snapshot schedule.
HEREDOC
type = number
default = 12
}
# ------------------------------------------------------------------------------
# MONGODB TAGS
# ------------------------------------------------------------------------------
variable "application" {
description = <<HEREDOC
Optional - Key-value pairs that tag and categorize the cluster for billing and organizational purposes.
HEREDOC
type = string
}
variable "environment" {
description = <<HEREDOC
Optional - Key-value pairs that tag and categorize the cluster for billing and organizational purposes.
HEREDOC
type = string
}
# ------------------------------------------------------------------------------
# MONGODB DATA
# ------------------------------------------------------------------------------
variable "project_name" {
description = <<HEREDOC
Required - The name of the Atlas project in which to create the cluster.
HEREDOC
type = string
}
We configured a file called locals.tf specifically to define two exemplary tags, aiming to identify the name of our application and the environment in which it operates. If you prefer, it is possible to adopt an external tag module, similar to those used in AWS, and integrate it into this configuration.
locals {
tags = {
name = var.application
environment = var.environment
}
}
In this article, we embrace the use of data sources in Terraform to establish a dynamic connection with existing resources, such as our MongoDB Atlas project. Specifically, in the data.tf file, we define a mongodbatlas_project data source to access information about an existing project based on its name:
data "mongodbatlas_project" "default" {
name = var.project_name
}
Here, var.project_name refers to the name of the project we want to query, an approach that allows us to keep our configuration flexible and reusable. The value of this variable can be provided in several ways, significantly expanding the possibilities for using our infrastructure as code.
The terraform.tfvars file is used to define variable values that will be applied in the Terraform configuration, making infrastructure as code more dynamic and adaptable to the specific needs of each project or environment. In your case, the terraform.tfvars file contains essential values for creating a cluster in MongoDB Atlas, including details such as the project name, cluster characteristics, and auto-scaling settings. See below how these definitions apply:
project_name = "project-test"
name = "cluster-demo"
cluster_type = "REPLICASET"
application = "teste-cluster"
environment = "dev"
region_configs = [{
provider_name = "AWS"
region_name = "US_EAST_1"
priority = 7
electable_specs = {
instance_size = "M10"
node_count = 3
disk_iops = 120
disk_size_gb = 10
ebs_volume_type = "STANDARD"
}
auto_scaling = {
disk_gb_enabled = true
compute_enabled = true
compute_scale_down_enabled = true
compute_min_instance_size = "M10"
compute_max_instance_size = "M30"
}
}]
These values defined in terraform.tfvars are used by Terraform to populate corresponding variables in your configuration. For example, if you have a module or feature that creates a cluster in MongoDB Atlas, you can reference these variables directly to configure properties such as the project name, cluster settings, and regional specifications. This allows significant flexibility in customizing your infrastructure based on different environments or project requirements.
The file structure was as follows:
main.tf: In this file, we will define the main resource, the
mongodbatlas_advanced_cluster, andmongodbatlas_cloud_backup_schedule. Here, you have configured the cluster and backup routines. provider.tf: This file is where we define the provider we are using — in our case, mongodbatlas. We will specify using environment variables, as mentioned previously.terraform.tfvars: This file contains the variables that will be used in our cluster. For example, the cluster name, cluster information, version, size, among others.
variable.tf: Here, we define the variables mentioned in the terraform.tfvars file, specifying the type and optionally a default value.
version.tf: This file is used to specify the version of Terraform and the providers we are using.
data.tf: Here, we specify a data source that will bring us information about our created project. We will search for its name and for our module, it will give us the project ID.
locals.tf: We specify example tags to use in our cluster.
Now is the time to apply. =D
We run a terraform init in the terminal in the folder where the files are located so that it downloads the providers, modules, etc…
Note: Remember to export the environment variables with the public and private keys.
export MONGODB_ATLAS_PUBLIC_KEY="public"
export MONGODB_ATLAS_PRIVATE_KEY="private"
Now, we run terraform init.
(base) samuelmolling@Samuels-MacBook-Pro cluster % terraform init
Initializing the backend...
Initializing provider plugins...
- Finding mongodb/mongodbatlas versions matching "1.14.0"...
- Installing mongodb/mongodbatlas v1.14.0...
- Installed mongodb/mongodbatlas v1.14.0 (signed by a HashiCorp partner, key ID 2A32ED1F3AD25ABF)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider selections it made above. Include this file in your version control repository so that Terraform can guarantee to make the same selections by default when you run `terraform init` in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running `terraform plan` to see any changes that are required for your infrastructure. All Terraform commands should now work.
If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
Now that init has worked, let’s run terraform plan and evaluate what will happen:
(base) samuelmolling@Samuels-MacBook-Pro cluster % terraform plan
data.mongodbatlas_project.default: Reading...
data.mongodbatlas_project.default: Read complete after 2s [id=65bfd71a08b61c36ca4d8eaa]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# mongodbatlas_advanced_cluster.default will be created
+ resource "mongodbatlas_advanced_cluster" "default" {
+ advanced_configuration = [
+ {
+ default_read_concern = "local"
+ default_write_concern = "majority"
+ fail_index_key_too_long = false
+ javascript_enabled = true
+ minimum_enabled_tls_protocol = "TLS1_2"
+ no_table_scan = false
+ oplog_size_mb = (known after apply)
+ sample_refresh_interval_bi_connector = 300
+ sample_size_bi_connector = 100
+ transaction_lifetime_limit_seconds = 60
},
]
+ backup_enabled = true
+ cluster_id = (known after apply)
+ cluster_type = "REPLICASET"
+ connection_strings = (known after apply)
+ create_date = (known after apply)
+ disk_size_gb = 10
+ encryption_at_rest_provider = (known after apply)
+ id = (known after apply)
+ mongo_db_major_version = "7.0"
+ mongo_db_version = (known after apply)
+ name = "cluster-demo"
+ paused = (known after apply)
+ pit_enabled = true
+ project_id = "65bfd71a08b61c36ca4d8eaa"
+ root_cert_type = (known after apply)
+ state_name = (known after apply)
+ termination_protection_enabled = (known after apply)
+ version_release_system = (known after apply)
+ bi_connector_config {
+ enabled = false
+ read_preference = "secondary"
}
+ replication_specs {
+ container_id = (known after apply)
+ id = (known after apply)
+ num_shards = 1
+ zone_name = "ZoneName managed by Terraform"
+ region_configs {
+ priority = 7
+ provider_name = "AWS"
+ region_name = "US_EAST_1"
+ analytics_auto_scaling {
+ compute_enabled = (known after apply)
+ compute_max_instance_size = (known after apply)
+ compute_min_instance_size = (known after apply)
+ compute_scale_down_enabled = (known after apply)
+ disk_gb_enabled = (known after apply)
}
+ analytics_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 0
}
+ auto_scaling {
+ compute_enabled = true
+ compute_max_instance_size = "M30"
+ compute_min_instance_size = "M10"
+ compute_scale_down_enabled = true
+ disk_gb_enabled = true
}
+ electable_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 3
}
+ read_only_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 0
}
}
}
+ tags {
+ key = "environment"
+ value = "dev"
}
+ tags {
+ key = "name"
+ value = "teste-cluster"
}
}
# mongodbatlas_cloud_backup_schedule.default will be created
+ resource "mongodbatlas_cloud_backup_schedule" "default" {
+ auto_export_enabled = (known after apply)
+ cluster_id = (known after apply)
+ cluster_name = "cluster-demo"
+ id = (known after apply)
+ id_policy = (known after apply)
+ next_snapshot = (known after apply)
+ project_id = "65bfd71a08b61c36ca4d8eaa"
+ reference_hour_of_day = 3
+ reference_minute_of_hour = 30
+ restore_window_days = 3
+ update_snapshots = false
+ use_org_and_group_names_in_export_prefix = (known after apply)
+ policy_item_daily {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "days"
+ retention_value = 7
}
+ policy_item_hourly {
+ frequency_interval = 12
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "days"
+ retention_value = 3
}
+ policy_item_monthly {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "months"
+ retention_value = 12
}
+ policy_item_weekly {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "weeks"
+ retention_value = 4
}
}
Plan: 2 to add, 0 to change, 0 to destroy.
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run `terraform apply` now.
Show! It was exactly the output we expected to see, the creation of a cluster resource with the backup policies. Let’s apply this!
When running the terraform apply command, you will be prompted for approval with yes or no. Type yes.
(base) samuelmolling@Samuels-MacBook-Pro cluster % terraform apply
data.mongodbatlas_project.default: Reading...
data.mongodbatlas_project.default: Read complete after 2s [id=65bfd71a08b61c36ca4d8eaa]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# mongodbatlas_advanced_cluster.default will be created
+ resource "mongodbatlas_advanced_cluster" "default" {
+ advanced_configuration = [
+ {
+ default_read_concern = "local"
+ default_write_concern = "majority"
+ fail_index_key_too_long = false
+ javascript_enabled = true
+ minimum_enabled_tls_protocol = "TLS1_2"
+ no_table_scan = false
+ oplog_size_mb = (known after apply)
+ sample_refresh_interval_bi_connector = 300
+ sample_size_bi_connector = 100
+ transaction_lifetime_limit_seconds = 60
},
]
+ backup_enabled = true
+ cluster_id = (known after apply)
+ cluster_type = "REPLICASET"
+ connection_strings = (known after apply)
+ create_date = (known after apply)
+ disk_size_gb = 10
+ encryption_at_rest_provider = (known after apply)
+ id = (known after apply)
+ mongo_db_major_version = "7.0"
+ mongo_db_version = (known after apply)
+ name = "cluster-demo"
+ paused = (known after apply)
+ pit_enabled = true
+ project_id = "65bfd71a08b61c36ca4d8eaa"
+ root_cert_type = (known after apply)
+ state_name = (known after apply)
+ termination_protection_enabled = (known after apply)
+ version_release_system = (known after apply)
+ bi_connector_config {
+ enabled = false
+ read_preference = "secondary"
}
+ replication_specs {
+ container_id = (known after apply)
+ id = (known after apply)
+ num_shards = 1
+ zone_name = "ZoneName managed by Terraform"
+ region_configs {
+ priority = 7
+ provider_name = "AWS"
+ region_name = "US_EAST_1"
+ analytics_auto_scaling {
+ compute_enabled = (known after apply)
+ compute_max_instance_size = (known after apply)
+ compute_min_instance_size = (known after apply)
+ compute_scale_down_enabled = (known after apply)
+ disk_gb_enabled = (known after apply)
}
+ analytics_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 0
}
+ auto_scaling {
+ compute_enabled = true
+ compute_max_instance_size = "M30"
+ compute_min_instance_size = "M10"
+ compute_scale_down_enabled = true
+ disk_gb_enabled = true
}
+ electable_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 3
}
+ read_only_specs {
+ disk_iops = (known after apply)
+ ebs_volume_type = "STANDARD"
+ instance_size = "M10"
+ node_count = 0
}
}
}
+ tags {
+ key = "environment"
+ value = "dev"
}
+ tags {
+ key = "name"
+ value = "teste-cluster"
}
}
# mongodbatlas_cloud_backup_schedule.default will be created
+ resource "mongodbatlas_cloud_backup_schedule" "default" {
+ auto_export_enabled = (known after apply)
+ cluster_id = (known after apply)
+ cluster_name = "cluster-demo"
+ id = (known after apply)
+ id_policy = (known after apply)
+ next_snapshot = (known after apply)
+ project_id = "65bfd71a08b61c36ca4d8eaa"
+ reference_hour_of_day = 3
+ reference_minute_of_hour = 30
+ restore_window_days = 3
+ update_snapshots = false
+ use_org_and_group_names_in_export_prefix = (known after apply)
+ policy_item_daily {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "days"
+ retention_value = 7
}
+ policy_item_hourly {
+ frequency_interval = 12
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "days"
+ retention_value = 3
}
+ policy_item_monthly {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "months"
+ retention_value = 12
}
+ policy_item_weekly {
+ frequency_interval = 1
+ frequency_type = (known after apply)
+ id = (known after apply)
+ retention_unit = "weeks"
+ retention_value = 4
}
}
Plan: 2 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
mongodbatlas_advanced_cluster.default: Creating...
mongodbatlas_advanced_cluster.default: Still creating... [10s elapsed]
mongodbatlas_advanced_cluster.default: Still creating... [8m40s elapsed]
mongodbatlas_advanced_cluster.default: Creation complete after 8m46s [id=Y2x1c3Rlcl9pZA==:NjViZmRmYzczMTBiN2Y2ZDFhYmIxMmQ0-Y2x1c3Rlcl9uYW1l:Y2x1c3Rlci1kZW1v-cHJvamVjdF9pZA==:NjViZmQ3MWEwOGI2MWMzNmNhNGQ4ZWFh]
mongodbatlas_cloud_backup_schedule.default: Creating...
mongodbatlas_cloud_backup_schedule.default: Creation complete after 2s [id=Y2x1c3Rlcl9uYW1l:Y2x1c3Rlci1kZW1v-cHJvamVjdF9pZA==:NjViZmQ3MWEwOGI2MWMzNmNhNGQ4ZWFh]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
This process took eight minutes and 40 seconds to execute. I shortened the log output, but don’t worry if this step takes time.
Now, let’s look in Atlas to see if the cluster was created successfully…
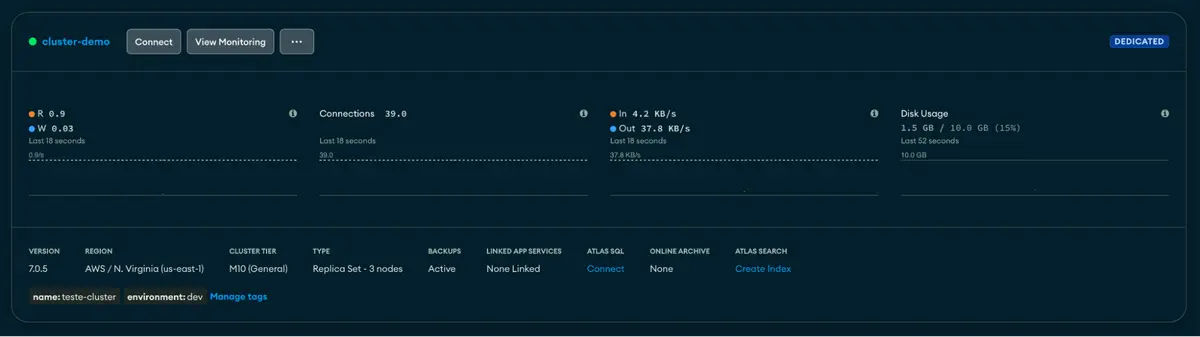
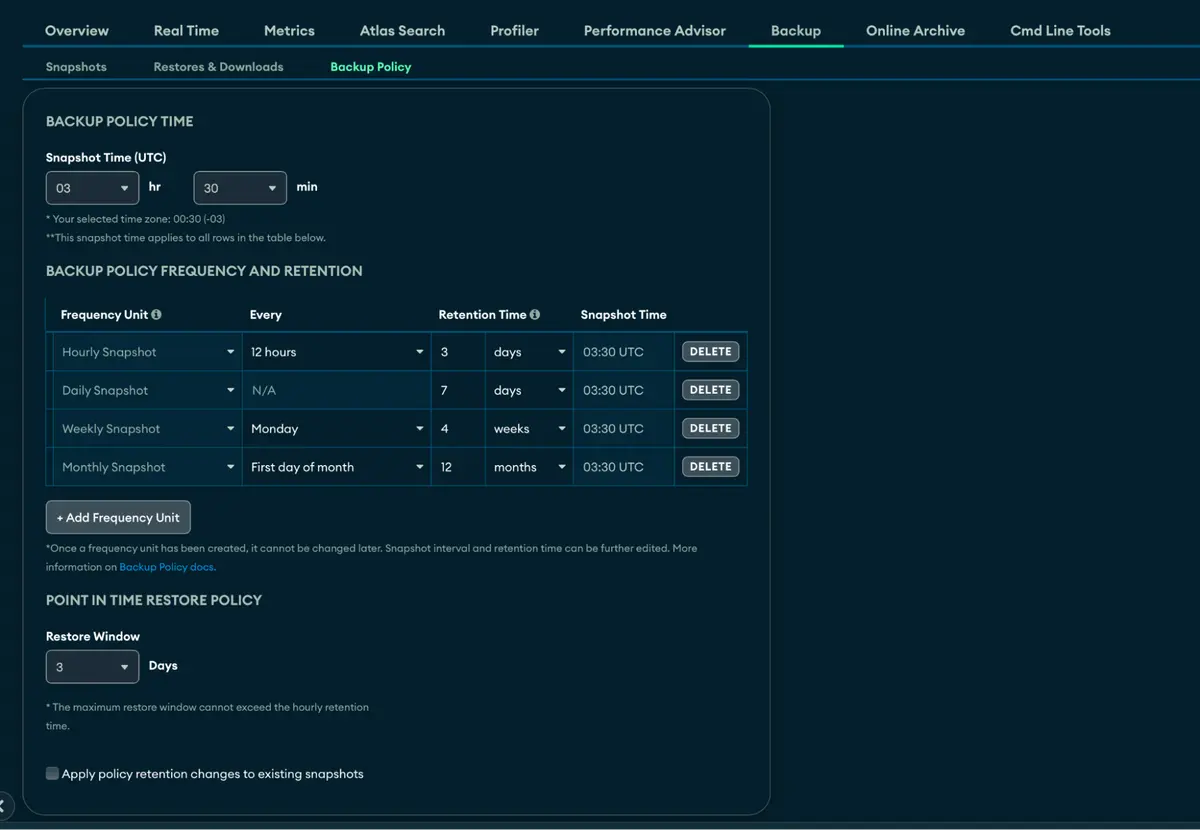
We were able to create our first replica set with a standard backup policy with PITR and scheduled snapshots.
In this tutorial, we saw how to create the first cluster in our project created in the last article. We created a module that also includes a backup policy. In an upcoming article, we will look at how to create an API key and user using Terraform and Atlas.
To learn more about MongoDB and various tools, I invite you to visit the Developer Center to read the other articles.